hadoop, part 3: graph-based nlp
I've been evaluating graph-based methods for language analytics. At my previous employer, we used statistical parsing and non-parametric methods as a basis for semantic analysis of texts. In other words, use a web crawler to grab some text content from a web page, run it through a natural language parser (after a wee bit o' clean-up), then use the resulting parse trees to extract meaning from the text. Typical stages required for parsing include segmentation, tokenizing, tagging, chunking, and possibly some post-processing after all that. Our use case was to identify noun phrases in the text, which is called NP chunking. Baseline metrics run at about 80% for success using that kind of approach.
More recent work on graph-based methods allows for improved results with considerably faster throughput rates. We did not apply this approach at HeadCase, but my tests subsequently have shown better than an order of magnitude performance gain, in terms of CPU time, when running side-by-side tests on the same processor and data set. This approach, based on link analysis within a graph, eliminates the need for chunking. Instead it iterates on a difference equation, which tends to converge rather quickly (depending on the size of the graph).
 source: wikipedia.org
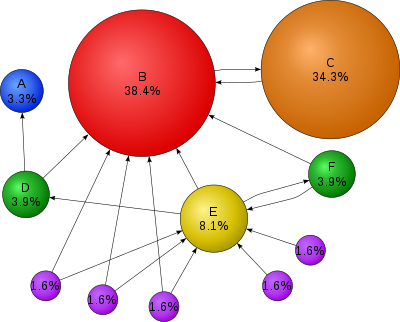
source: wikipedia.orgAs an example, I took input text from an encyclopedia article about Java Island found online. It has 3 paragraphs, 16 sentences, 331 words, 2053 bytes. Using a popular, open source NLP library, a parser-based approach for identifying noun phrases takes an average of 8341 milliseconds on my MacBook laptop, while the same task using the same libraries with a graph-based approach takes an average of 257 milliseconds. That's a factor 32x speed-up.
To be fair, some researchers have used tagging followed by regular expressions to perform fairly good NP chunking. That works, quickly, but not so well. I needed better results.
The following table illustrates the success of the two approaches, compared with the top 27 key phrases selected by a human editor:

While the graph-based approach has a higher error rate, in terms of recognizing actual noun phrases, it results in comparable F-measure precision rates – with single digital relative error between the two approaches. That is accounted for by the fact that each step in a stochastic parser introduces some error and ambiguity because of variants, but a relatively simple use of dynamic programming can be applied to prune variants and reduce error overall. In contrast, a graph-based analysis tends to identify better high-value targets for key phrases – and more importantly, it tends to rank true positives higher than the noise, which is not something that a parser-based approach can provide. If there is post-processing involved for contextual analysis, the noun phrases produced by a graph-based approach appear superior – and substantially more performant.
Another point to consider, when analyzing large amounts of text, is that graph-based analysis is relatively simple and efficient to implement using a map-reduce framework such as Hadoop.
The trick is… how to represent a stream of morphemes in natural language as a graph.


No comments:
Post a Comment