[Ed: the diagram shown below has been updated; see previous diagram and the discussion update.]
I got asked to join to a system architecture review recently. The subject was a plan for data center redundancy. The organization had one data center, and included some relatively big iron:
- a large storage system appliance, with high capex (its name starts with an "N", let you guess)
- a large RDBMS with expensive licensing (its name starts with an "O", let you guess)
- a large data warehouse appliance, with GINORMOUS capex, expensive maintenance fees, and far too much downtime (its name includes a "Z", let you guess)
- plus several hundred Linux servers on commodity hardware running a popular virtualization product (its name includes an "M" and a "W", let you guess)
The plan was to duplicate those resources in another data center, then run both at 50% capacity while replicating data across them. In the event of an outage at one data center, the other would be ready to handle the full load.
Trouble is, most of those
Ginormous capexii species of products – particularly the noisome
Ginormous capexii opexii subspecies – were already heavily overloaded by the organization. That makes the "50% capacity" load balancing story hard to believe. Otherwise it would have been a good approach, circa 2005. These days there are better ways to approach the problem...
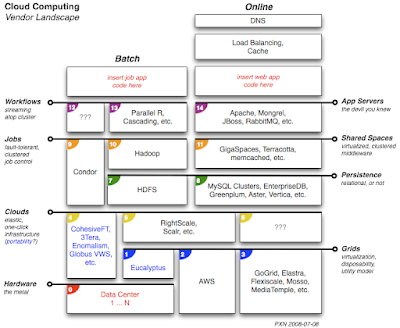
After reviewing the applications it became clear that the data management needed help – probably before any data centers got replicated. One immediate issue concerned unwinding dependencies on their big iron data management, notably the large RDBMS and DW appliance. Both were abused at the application level. One should use an RDBMS as, say, a backing store for web services that require transactions (not as a log aggregator), or for reporting. One should use a DW for storing operational data which isn't quite ready to archive (not for cluster analysis).
We followed an approach: peel off single applications out of that tangled mess first. Some could run on MySQL. Others were periodic batch jobs (read: large merge sorts) which did not require complex joins, and could be refactored as Hadoop jobs more efficiently. Perhaps the more transactional parts would stay in the RDBMS. By the end of the review, we'd tossed the DW appliance, cut RDBMS load substantially, and started to view the filer appliance as a secondary storage grid.
Another approach I suggested was to think of cloud computing as the "duplicating 50% capacity" argument taken to the next level. Extending our "peel one off" approach, determine which applications could run on a cloud – without much concern about "where" the cloud ran other than the fact that we could move required data to it. Certainly most of the Hadoop jobs fit that description. So did many of the MySQL-based transactions. Those clouds could migrate to different grids, depending on time, costs, or failover emergencies.
One major cost is data loading across grids. However, the organization gains by duplicating its most critical data onto different grids and has a business requirement to do so.
In terms of grids, the organization had been using AWS for some work, but had fallen into a common trap of thinking "Us (data center) versus Them (AWS)", arguing about TCO, vendor lock-in, etc. Sysadmins calculated a ratio of approximately 3x cost at AWS – if you don't take scalability into consideration. In other words, if a server needs to run more than 8 hours per day, it starts looking cheaper to run on your own premises than to run it on EC2.
I agree with the ratio; it's strikingly similar to the 3x markup you find buying a bottle of good wine at any decent restaurant. However, scalability is a crucial matter. Scaling up as a business grows (or down, as it contracts) is the vital lesson of Internet-based system architecture. Also, the capacity to scale up failover resources
rapidly in the event of an emergency (data center lands under an F4 tornado) is much more compelling than TCO.
In the diagram shown above, I try to show that AWS is a vital resource, but not the only vendor involved. Far from that, AWS provides services for accessing really valuable metal; they tend to stay away from software, when it comes to cloud computing. Plenty of other players have begun to crowd that market already.
I also try to separate application requirements into
batch and
online categories. Some data crunching work can be scheduled as batch jobs. Other applications require a 24/7 presence but also need to scale up or down based on demand.
What the diagram doesn't show are points where message queues fit – such as Amazon's SQS or the open source
AMPQ implementations. That would require more of a cross-section perspective, and, well, may come later if I get around to a 3D view. Frankly, I'd rather redo the illustration inside Transmutable, because that level of documentation for architectures belongs in real architectural tools such as 3D spaces. But I digress.
To me, there are three aspects of the landscape which have the most interesting emerging products and vendors currently:
- data management as service-in-the-cloud, particularly the non-relational databases (read: BigTable envy)
- job control as service-in-the-cloud, particularly Hadoop and Condor (read: MapReduce+GFS envy, but strikingly familiar to mainframe issues)
- cloud service providing the cloud (where I'd be investing, if I could right now)
A Methodology
To abstract and summarize some of the methodology points we developed during this system architecture review:
- Peel off the applications individually, to detangle the appliance mess (use case analysis).
- Categorize applications as batch, online, heavy transactional, or reporting – where the former two indicate likely cloud apps.
- Think of cloud computing as a way to load balance your application demands across different grids of available resources.
- Slide the clouds across different grids depending on costs, scheduling needs, or failover capacity.
- Take the hit to replicate critical data across different grids, to have it ready for a cutover within minutes; that's less expensive than buying insurance.
- Run your own multiple data centers as internal grids, but have additional grid resources ready for handling elastic demands (which you already have, in quantity).
- Reassure your DBAs and sysadmins that their roles are not diminished due to cloud computing, and instead become more interesting – with hopefully a few major headaches resolved.
Meanwhile, keep an eye on the vendors for non-relational data management. It's poised to become suddenly quite interesting.
My diagram is a first pass, drafted the night after our kids refused to sleep because of a thunderstorm... subject to many corrections at least a few revisions. The vendors shown on fit approximately, circa mid-2008. Obviously some offer overlapping services into other areas. Most vendors mentioned are linked in my public bookmark:
http://del.icio.us/ceteri/gridComments are encouraged. Haven't seen this kind of "vendor landscape" diagram elsewhere yet. If you spot one in the wild elsewheres, please let us know.



{kind=link}
{kind=link}